

Non-agentic data science
Adding to the list of axes along which we can segment data science. Agentic data science is lots of low-stakes decisions. Non-agentic is a small number of high stakes decisions.
In some sense I specialise in coming up with axes along with one can segment data scientists. Maybe this comes out of having worked in the field for as long as I have, and in trying to carve my own space within this.
Prior attempts at classification
Most recently, I wrote about data scientists who can find insights and data scientists who can put things into production; and I had written a year ago about how the two are different skills and not usually found in the same person.
That was written from the point of view of hiring for my then company, but these lines are pertinent:
I’m Type 1 according to this classification, for example. In a previous organisation, I ended up hiring lots more Type 1s. That worked well until I started reporting into a technical person who demanded that all our analyses “be put into production”. Suddenly the lack of Type 2s in my team became a massive liability.
If you look at a conventional data science team in any company, you’ll see that they overindex on type 2. This leads to impeccable code and great software engineering practices but suboptimal models and logic.
Back in 2017, I had come up with another axis - high dimensional and low dimensional data scientists, in terms of the kind of data modelling they specialise in. When you are working with data with a lot of “dimensions”, the old-school techniques of inspecting data, finding distributions and statistics and correlations, finding goodness of fit, and all that become irrelevant/ infeasible. You are best placed to just “stir the pile”.
However, when you have few dimensions of data, then stirring the pile can be suboptimal. You should go about things the “old way” - inspecting and understanding the data, figuring out distributions, and all that.
Agentic and non-agentic data science
Now, this being 2026, and everything having to be “agentic”, I’m coming up with yet another classification, which admittedly has high correlation with some of the other classifications I’ve come up with. This is about how the output of data science gets used.
Fundamentally, you don’t analyse data just for the sake of it. Like people are not yet tired of saying, all analysis needs to be “actionable”. This axis basically has to do with what kind of actions can be taken based on the insights from the data.
There are fundamentally two extremes.
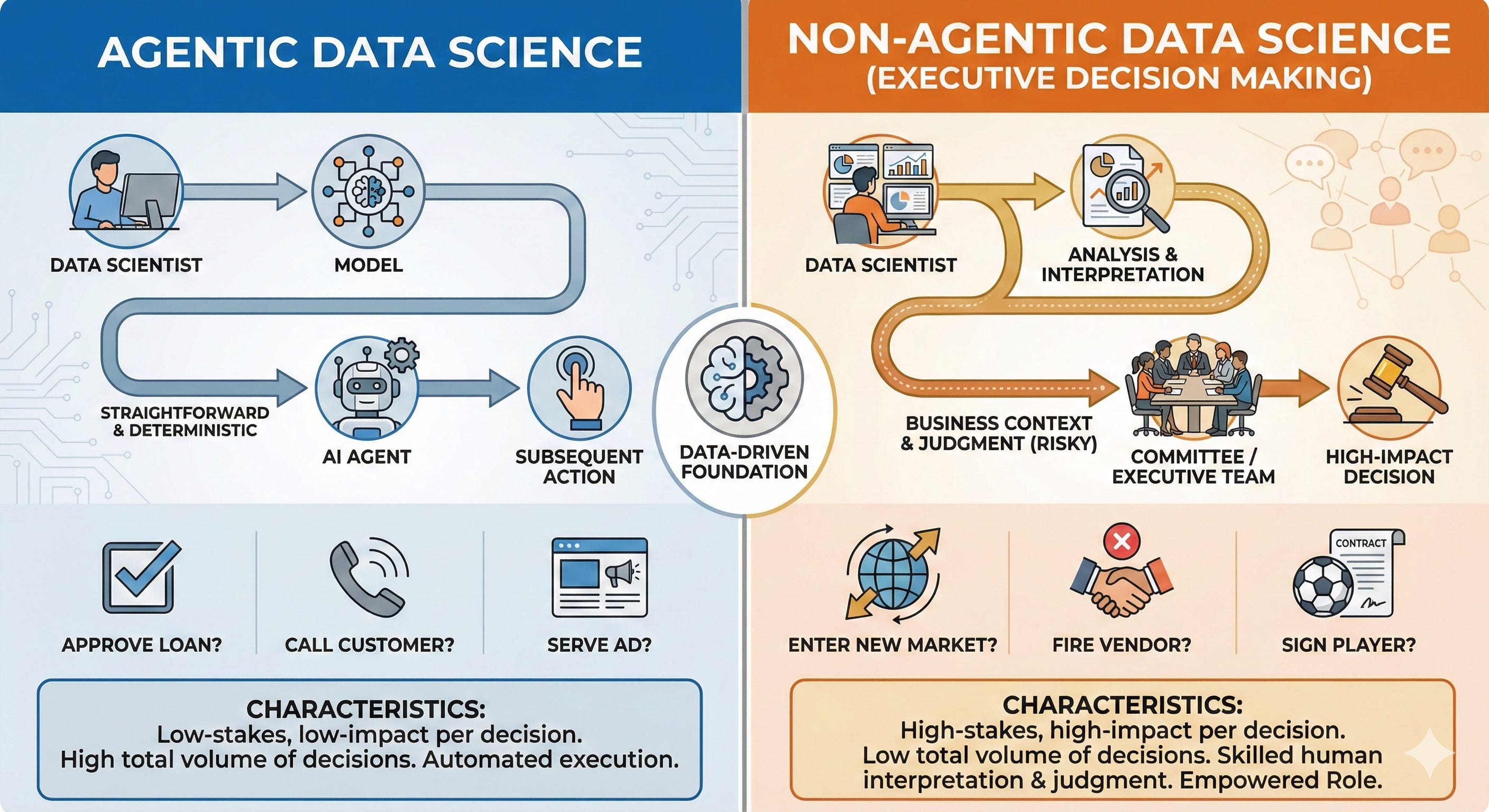
The first is what I’ll now call “agentic data science”. Here, the data scientist builds a model, which produces some output. In this case, the translation from the data output to the ultimate business decision is rather straightforward and deterministic. Even if it is not perfectly deterministic, it is deterministic enough that you can simply plug an AI agent to the end of it, that will inspect the output and take the subsequent action.
Typically, these end up being decisions where each individual decision is low-stakes and low-impact, but one needs to make loads of such decisions in a day, because of which the “total volume of decisions” will be high.
Examples of such decisions are: “should I approve this loan?”, “should I call this customer today?”, “should I serve this ad to this user?” etc.
At the other extreme, you have “executive decision making”. Here, the path from data to decision is less straightforward. Irrespective of how much analysis you do, the analysis can only take you so far. What one needs after that is skilled interpretation, that combines the output of the analysis with business context and judgment.
This interpretation is necessarily risky. The number of such decisions is small, but each decision is of extremely high impact. It is unlikely that one person makes the decision here - it often gets deferred to a committee, which the data scientist in charge is part of.
Typically, an empowered data scientist’s job here doesn’t end at producing the analysis - they are also responsible for interpreting it in the context of the company and business, and recommending a way of action. In a way, this is a riskier role, but a higher impact role.
Examples of decisions that are made this way - “should we enter this market”, “should we fire this vendor”, “should this football club sign this player” etc. Irrespective of how data-driven the decision is, the fine margins and binary nature of decisions means there is a huge aspect of judgment involved.
Given the zeitgeist, I term this as “non agentic data science”. You might vibe code your way through the analysis leading up to the decision, but given the impact of the decision you will necessarily double-check it. Once you have the analysis, it is your opinion that matters after that, not the average opinion of the internet on that matter - and so using an LLM is not always appropriate.
In any case, my use of the word “agentic” here is just to ride the zeitgeist. For years now, we’ve had machine learning models deployed in production where an if-else statement (or a chain of such statements) have effectively done things based on the output of the data science model. Agents just make it a bit less predictable!
That said, agents will always be used for high-volume low-stakes decisions. They won’t be needed for low-volume high-stakes decisions.
Correlations
Having written this blogpost so far, I realise that this classification is rather correlated with my previous classification - of insight-first and code-first data scientists. In fact, I’m now superseding that classification with this one.
If you are a non-agentic data scientist, then you are primarily working on building tools for one-time decisions. And that means that you don’t necessarily need to put your code (assuming it exists in one place) into production. That makes you, according to my previous classification, a “insight-first data scientist”.
If you are an agentic data scientist, building systems that agents can take actions based on, then your code better be in production, for there is no other way agents can act on it. This automatically means that you become a “code first data scientist”.
And you know that the skills required for these two can be rather different!
Sundries
Suddenly I’m thinking of my company Babbage Insight, that I ran for the last two years, where we were using AI to help CXOs make better decisions using data. I’m wondering if we were trying to solve a non-agentic data science problems in an agentic manner!
All data science is opinionated, but some data science problems are more opinionated than others. The ones that are less opinionated are easier to vibe code (I wrote this in my last post).
Whatever you describe as Agentic Data Science is already being done without Agents using ML models for many years now no? And the Non-Agentic DS that you talk about - it is difficult for the Data Scientist to be part of this decision making group if they are internal. It might work if an external consulting Org which has a lot of credibility with the management brings the data insight. Otherwise the opinion of the Data Scientist might get dismissed for the sole reason that they are not 'business'