
The Art of Data Science: Chapter Three
Should we understand our models?
I ended the last newsletter with what can be described as a "handle". I recommended Matt Levine's newsletter, and left you with an extract from it that linked to a MIT Technology Review article on Artificial Intelligence (AI). I didn't mention it then in that many words, but I strongly recommend you to read that article.
The basic concept is that artificial intelligence is getting ahead of us, and that it is nearly impossible for us to understand and explain a lot of the models that some machine learning systems are producing. Frequently, these models are "good" (in terms of the proportion of the time when they predict correctly), but there is no way for us to understand the inner workings of the model.
This is especially the case with methods such as deep learning, which are nearly impossible to reverse engineer. It is fashionable to explain deep learning to a lay person in the way that this article does:
In a system designed to recognize dogs, for instance, the lower layers recognize simple things like outlines or color; higher layers recognize more complex stuff like fur or eyes; and the topmost layer identifies it all as a dog.
While such systems do a great job of identifying dogs, it is impossible for us to know if it actually went from outlines to fur to dog, or followed some other path. For the parameters in each part of the model are so fragmented that it is impossible for a human examining the code (or output) to know what exactly it was about an image that made the system recognise it as a dog.
The question of whether we should be able to understand our models is not an easy one to answer. On the one hand, if we insist we understand, we might end up missing out on several great models (maths is generally a few steps ahead of human understanding). On the other, models we don't understand might end up building fragility in our system - which can hit us hard at a time when there is some sort of a "regime change" in the system, and the model starts behaving badly.
I might be biased given my background in economics and financial markets. Having followed the 2008 Financial Crisis rather closely, I be bloody spooked to use a model that I may not understand fully - it can introduce several hidden risks into my system. However, if you come from the hard sciences, where the chances of a regime change are incredibly low, you might be more sympathetic to black box models.
Anyway, read the full article. It talks about some efforts to try and understand how neural networks do their job. It's mostly fascinating stuff.
The Science of Data Science
In the very first edition of this newsletter, I'd linked to this article in the Harvard Business Review by DJ Patil (later Chief Data Scientist of the United States) and Thomas Davenport of Babson College. This is the article where they defined "data scientist" to be the "sexiest job of the 21st century". I recently re-read this article carefully, and noticed something I'd not seen earlier.
For a while now I've noticed that a large number of data science jobs are held by people with PhDs. And these are not PhDs in maths, computer science or statistics - traditional professions that you'd expect to do well in data science. Instead, you see a large number of people with PhDs in pure sciences doing data science. Quite a few of them have a postdoc or two as well.
You'd be forgiven to think that these people are victims of the imbalance between the number of tenure track and grad student positions in pure sciences (I'd encourage you to read this New York Times article on the topic). Reading Patil and Davenport's article carefully suggests, however, that companies might be making a deliberate attempt at recruiting pure science PhDs for data scientist roles.
The following excerpts from the article (which possibly shaped the way many organisations think about data science) can help us understand why PhDs are sought after as data scientists.
Data scientists’ most basic, universal skill is the ability to write code. This may be less true in five years’ time (Ed: the article was published in late 2012, so we're almost "five years later" now)
Perhaps it’s becoming clear why the word “scientist” fits this emerging role. Experimental physicists, for example, also have to design equipment, gather data, conduct multiple experiments, and communicate their results.
Some of the best and brightest data scientists are PhDs in esoteric fields like ecology and systems biology.
It’s important to keep that image of the scientist in mind—because the word “data” might easily send a search for talent down the wrong path
Patil and Davenport make it very clear that traditional "data analysts" may not make for great data scientists.
MS Excel
I spent only three months in my first full time job, but during that period I learnt an invaluable life skill - using Visual Basic to write code in Excel. It was a gamechanger in terms of how I used the software - it was now possible to build models that were an order of magnitude more complex than what I could build earlier (and Excel is anyway designed to build models with complex linkages).
The advantage with Visual Basic was that I could now actually program Excel. Where there were repeated procedures I could simply replace with code which would repeat the process. It wasn't long before I started writing fairly complex algorithms to manipulate data using Excel. And Excel's inherent slowness and clunkiness meant that for the first time I actually put to use the algorithm analysis and design concepts I'd learnt in my undergrad.
The beauty of coding in Excel-VBA is that you can see the results of your coding and analysis "live", and it is far easier to debug code. I once spent a year writing a program in Java, where debugging had been a nightmare. It then took me only a month to replicate the program in Excel, entirely bug-free, and with beautiful visual outputs (yes, Excel graphs can be made to look beautiful. More on that in another edition).
However, it's been eight years now since I stopped using Excel for my data analysis. The problem is that while VBA allows you to write scripts, and it simplifies limited tasks, there are limits to this automation. Consider, for example, a piece of analysis you need to perform every month based on (let's say) your company's sales data for that month.
In Excel, the data has to be manually downloaded and copy-pasted, and older data moved physically, and the formulae and code changed appropriately that it continues to work with the new data. Some of this can be done intelligently (like automatically dragging the formulae, etc.), but some degree of manual intervention is needed. And manual intervention means scope for error. And you want to eliminate that. Moreover, while Excel now supports larger datasets, it can get slow when the size of the dataset grows.
Data analysis packages such as R, on the other hand, enable you to script end-to-end. From pulling data from databases (or wherever else it's stored), to appending it to the existing data to doing whatever analysis you want and producing reports in a beautiful format (with some effort, you can create entirely automated PDF reports and even get the program to mail it to a chosen set of recipients.
I haven't fully given up on Excel, though. When the size of the data is small, there isn't much statistical analysis to do, and the linkages between different numbers in the data rather complex, Excel is by far the best tool you can use. And the fact that so many other people understand it is a massive bonus!
Charts of the edition
This edition, we discuss not one chart, but two. And one of those is a GIF. And both the charts are "meta" in the sense that they were drawn not to represent some data but to introduce a particular concept. I came across both via Twitter.
Since the 1980s, it has been conventional wisdom among people doing data visualisation that pie charts don't do a great job of communicating data. Basically, the human eye cannot intuitively measure areas as well as it measures lengths. Pie charts indicate the quantities in terms of the areas of pies, and that makes them hard to read.
What makes them worse is that since the different portions of the pie are arranged in a circular fashion, it is not easy to compare them directly. Anyway, I'll let the first chart of the edition do the talking. This is from a tweet by Max Roser.
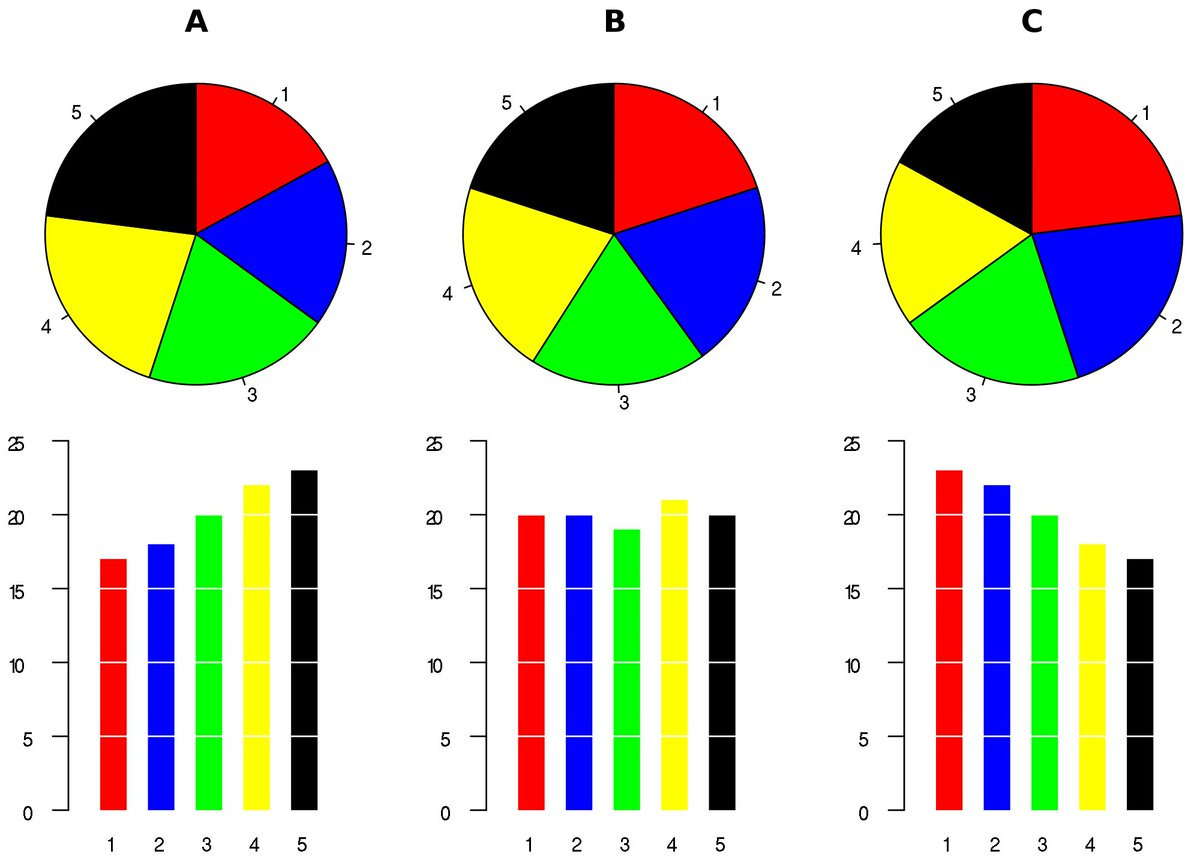
The three pies look indistinguishable, except that they represent completely different distributions of the data. Look how clear the bars make the differences in quantities appear, while the pie charts do none of that. At a meta level, this is a great visualisation by Max Roser to illustrate something I (and other data visualisation people) have been pontificating for years.
Now for the gif. This is related to something we've discussed upthread - whether we should understand the models we build. When we use black box models (effectively letting computers build the model), we don't usually bother with inspecting the data ourselves, and at best rely on summary statistics. This visualisation by Autodesk research is an enhanced version of the famous Anscombe's Quartet, but the GIF format and the use of the creature makes it far more entertaining.

All these data sets have the same means, standard deviations and correlation coefficients between the X and Y values. As you can see, however, each of them represents a wholly different distribution! Autodesk calls it the "datasaurus dozen".
I guess I've given away too much on where I lie on the topic of whether you should understand your data and your models!
Links
If you want a regular dose of fundaes on visualisation, you should follow this blog called "Junk Charts", written by Kaiser Fung. Fung basically does, more regularly and in a more rigorous manner, what I do in the "chart of the edition" section of this newsletter - take a visualisation and then dissect it. The good thing about Fung is that he's quite pragmatic in his analysis.
Fung also writes another blog called "numbers rule your world". This is more on data analysis, and he does with analysis what he does in Junk Charts with charts. Again highly recommended.
What I wouldn't recommend by Fung is his book Numbersense. I bought it on Kindle, and found it rather unreadable. Couldn't get past 10% or so. Basically it was full of stuff that was fairly obvious.
Elsewhere, I've written two pieces for Mint on the IPL. First, midway through the IPL, I looked at how team strategies have evolved over the last 10 years. And then I ranted about how the IPL schedule is badly designed.
Then, Praveen Jayachandran (JP), who was my classmate at IIT Madras, has written an excellent primer on blockchains. It's a bit long, but well worth reading if you want to understand the fundamentals.
That's about it for this edition. I'll be back soon. In the meantime, share the newsletter with whoever you think might like it. And do keep the feedback coming!
Cheers
Karthik