

LLMs and PageRank
LLMs and PageRank
LLMs aren't very good at data analysis. I don't know if they use a PageRank kind of weighting to boost certain sources over others.
I’m fairly convinced that all the data analysis capabilities of LLMs are down to them being trained on data from answers on Kaggle. Yesterday, for example, I uploaded a dataset (a time series of my own daily weight, sleep “score”, etc.) and asked it to find trends. It failed spectacularly.
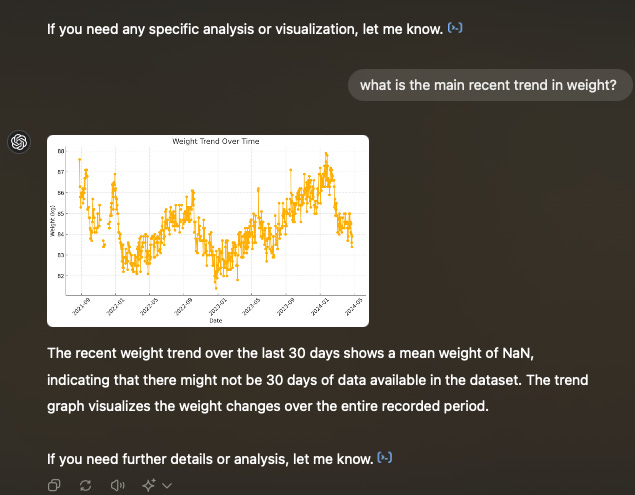
There is a clear trend, that you can see in the graph here, but ChatGPT (4o) was more worried about the NAs in the data than actually getting insight out of it. This sounds like a fairly poor junior analyst to me.
This is not the first time that I’ve been left disappointed by ChatGPT when it comes to data analysis. It seems to show all the signs that I see in a poor (or “junior”) data scientist - requiring too many instructions, not making enough informed assumptions, focussing more on the semantics and the methods than in the problem statement, being “too technical”, etc.
Last week I was listening to this podcast about AI from a16z.
In that they talk about how LLMs are basically an “average of the knowledge on the internet” (I’m clearly paraphrasing here. I know they said this when I was close to Ranga Shankara on my way to my daughter’s school for a meeting on Saturday morning, but don’t know where in the podcast that corresponds to!).
The reasoning is this - LLMs are trained on large corpuses of text, and the model learns to predict the next token given a series of tokens. Putting it very crudely, you can think of it as predicting the most probable next token based on the tokens so far, based on the data it’s been trained on. Putting it even more crudely, you take the series of tokens so far, search for them in your (vector) database and find the most probable next token and return it.
I’m oversimplifying here but what it means is that if the most popular continuation for a series of tokens is spurious, this spurious result is “learnt” by the LLM and returned.
The reason why LLMs aren’t natively very good at data analysis is that they are an average of the data analysis literature available on the internet. Which basically means the likes of Kaggle and a whole host of (personal and corporate) blogs. Without loss of generality, most of them are written by novices or people learning data science. And if you take the “wisdom of crowds average” of that, the result isn’t likely to be particularly good.
I was thinking about this in the context of Google’s PageRank (named after Larry Page, incidentally), that scores webpages based on the number and strength of the incoming links into the page. What made Google so good two decades ago is precisely this - ranking a page highly if it has incoming links from other high quality pages. This meant generally high quality results.
Now, I’m wondering - if LLMs actually implement some kind of a PageRank in order to weight the samples of text that they are trained on. That would mean that a blogpost doing data analysis having lots of (or high quality) incoming links would get a much higher weight than some obscure blogpost somewhere with no links. And with the original Google premise that high quality inbound links means higher quality page, this would result in a “better than average” system.
In any case, even if this were to be implemented, I’d still not be sure of the native data analysis capabilities of LLMs. After all it is still (a weighted) average of all the sources it has been trained on!
The average human data scientist is meek, and not opinionated enough. And I see the same thing about “LLM data scientists” as well.