

Data Cleaning
Data Cleaning
In which I argue that data cleaning is essentially a creative, hypothesis-driven process
A decade ago, when I was running my own analytics and data science consulting practice, a common question I would get was why I would not outsource the data cleaning part. My constant argument then was that by cleaning the data myself, I would get a much better feel for the data, which would lead to much better overall analysis. Now I have a slightly different take on this.
Conventionally, you think of data cleaning as a low value add, possibly “menial” process. This possibly has to do with the term “data cleaning” itself. And when you look at the way “bootcamp data scientists” approach data cleaning, it is understandable why someone would think that this is a process that can be easily outsourced or automated.
For example, I just asked ChatGPT (4o), the “aggregator of all Kaggle data science knowledge” how to clean data. This is what it said:
• Inspect the data:
• Look for missing values, duplicates, and inconsistent data types.
• Identify outliers and potential errors.
• Handle missing values:
• Remove rows or columns with too many missing values.
• Impute missing values using mean, median, mode, or more sophisticated methods.
• Remove duplicates:
• Drop duplicate rows to avoid redundant information.
• Correct data types:
• Convert columns to appropriate data types (e.g., strings to dates, integers to floats).
• Standardize values:
• Ensure consistent formatting (e.g., all text in lowercase, standardized date formats).
• Outlier treatment:
• Remove or transform outliers based on the context of the data.
• Feature engineering:
• Create new features or modify existing ones to better represent the data.
• Normalize/scale data:
• Apply normalization or scaling techniques if needed for algorithms.
• Data validation:
• Ensure the cleaned data meets the requirements and is free of errors.
As you can see, this seems rather “algorithmic”. However, if you think about the process you actually go through while cleaning, you realise that it is anything but algorithmic.
In fact, I will argue that data cleaning is as hypothesis-driven and creative as the entire data analysis process. You cannot clean data by simply following an algorithm.
Context sensitive cleaning
In order to clean data effectively, you need to inspect it. “Remove / fill missing values” sounds simple enough, but how you fill the values is dependent on what values are missing, and what the distribution of the rest of the values looks like.
For example, in some cases, it might make sense to delete entire rows that contain missing values. In other cases, you might want to fill them in. What action to take again depends on what the data looks like. And if you decide to fill in the values, what values to fill in (typically, but not always, mean or mode) is also highly dependent on observing the data and knowing what is there.
Then, knowing what data is “unclean” is also hazy, and dependent on the context. For example, as some of you know, I track a bunch of life-related metrics (weight, health, meal times, lifting, etc.) in one Excel sheet. Periodically I analyse the data. While doing some such analysis this morning, I saw that one column had three kinds of values - “Yes”, “yes” and “No”. Clearly on one day, I had entered “Yes” in the wrong case, and R (the tool I use for my data analysis) is case sensitive.
And so I knew that all “yes”s need to be converted to “Yes” (“Yes” was far more frequent that “yes” so I knew the direction in which to convert). Had I not inspected the data well enough, I may not have figured out this needs to be done. Actually - if I’d not inspected the data well enough, this anomaly would’ve been detected only when I did the analysis - at which point I would have fixed it (again notice that it’s an iterative process!).
So if you were to think of the data cleaning process, it is as “hypothesis driven” as any other data science process. The first step is well defined (“observe the data”), but nothing after that. You do one step, you look at the results and hypothesise, and that leads to the next step.
Cleaning → Analysis
What this means is that by the time you are done cleaning the data, you already have a bunch of observations and hypotheses to work with, and that quickly gets you on track with your analysis. You have a starting point before you have even begun the formal analysis.
If someone else (or some other algorithm) were to do the cleaning, all this valuable knowledge on the quirks of the data and what analysis needs to be done will be lost. And it will take much more time to start off on the data analysis process. In other words, you might as well have spent that time cleaning the data yourself, and saving the transaction cost of outsourcing it!
Why ChatGPT doesn’t cut it
For a year and a half now, people have been talking up the data analysis capabilities of LLMs. At a recent networking dinner, for example, the head of analytics of a large Indian company told me “don’t even bother doing anything in data analysis. The rate at which the LLMs are getting more impressive is not funny”.
The counterpoint to this is that ChatGPT is “arbit”. Sometimes it does superlatively on tasks that we’ve historically not seen AIs doing well in, and so we assign superhuman capabilities to it. What we fail to understand is that there are other situations where ChatGPT is actually superlatively bad.
And when it comes to data analysis, as things stand, it appears as if ChatGPT is an ensemble of Kaggle answers. Which means when it comes to data cleaning, it does it in the “boot camp” procedural non-iterative manner. For example, I gave it a subset of my daily tracking data and asked it to clean it. This is a part of the conversation:
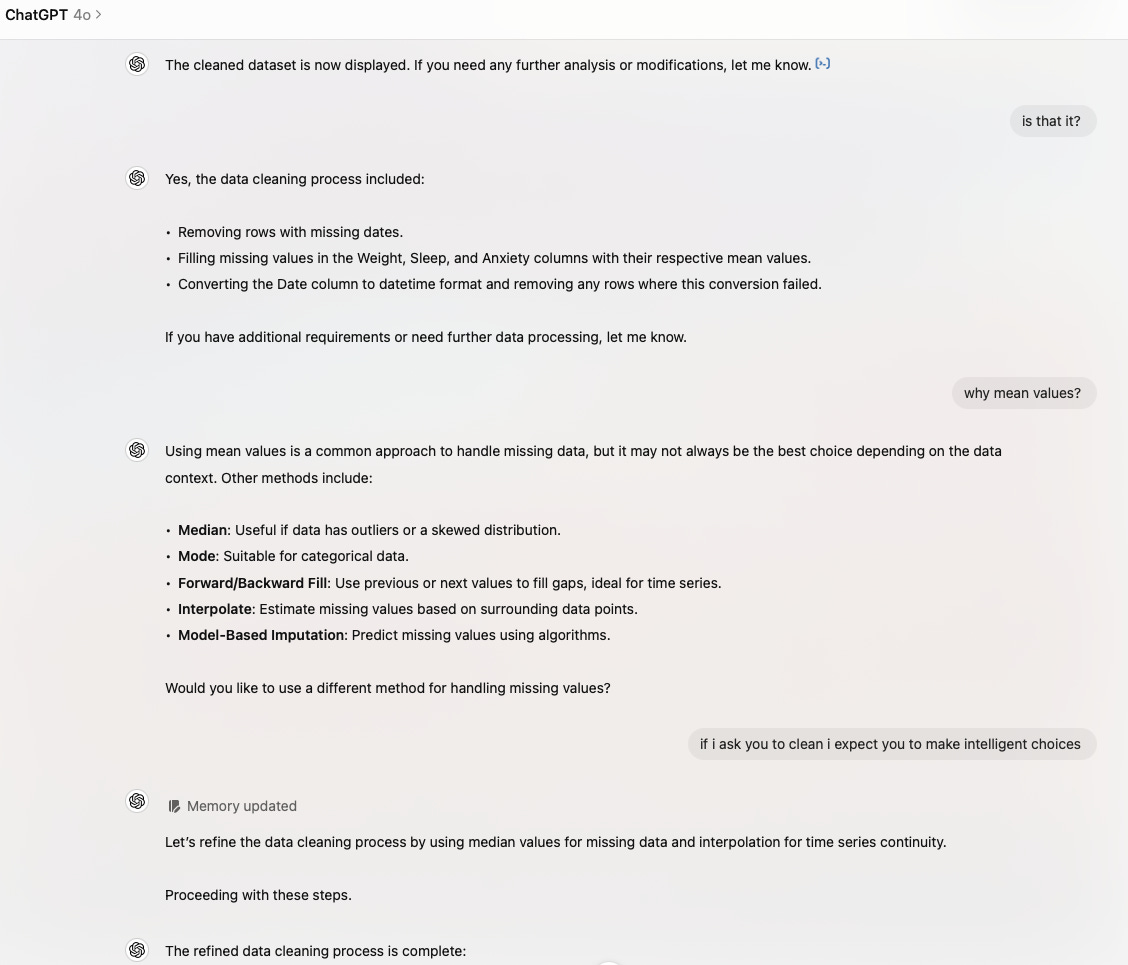
Actually, if this is the level of cleaning you desire - follow a bunch of pre-set instructions - then ChatGPT is not a bad option for you. The problem with this is that ChatGPT doesn’t truly clean the data here. And if you were to face any issues while doing the actual analysis, there is no way to go back and rectify things.
ChatGPT cannot analyse data
This is something all of us tend to frequently forget - chatGPT cannot natively analyse data. What it can do is to write code to analyse data. So, given a dataset, it figures out what code needs to be written in terms of analysing it. And then applies the code (with Code Interpreter (or whatever it is called now), it has the ability to run such code and see the outputs).
To the best of my knowledge it doesn’t really have the ability to see the outputs and then take the next step based on that - again a key process in the normal data analysis process. What it can at best do is to know if some analysis didn’t work (code not running), and tweaking the analysis accordingly.
This is the reason why you sometimes see disappointing analysis from it - for example, in my previous post, I gave an example where it found the mean to be “NA”, and instead of re-running the analysis by removing the missing values (the normal “human data scientist” thing to do), it simply said “the mean is NA so there may not be 30 data points” and gave up.
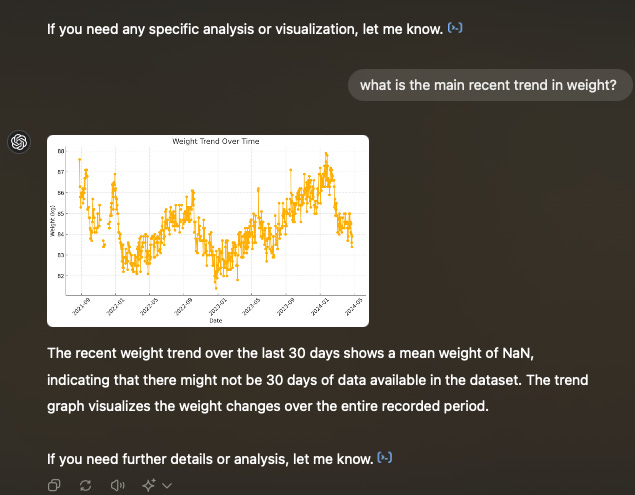{kind=link}
It remains to be seen how future versions of LLMs handle this kind of stuff.
PS: And as Subbarao Kambhampati never tires of tweeting, and I never tire of saying here, LLMs cannot plan.